Answers
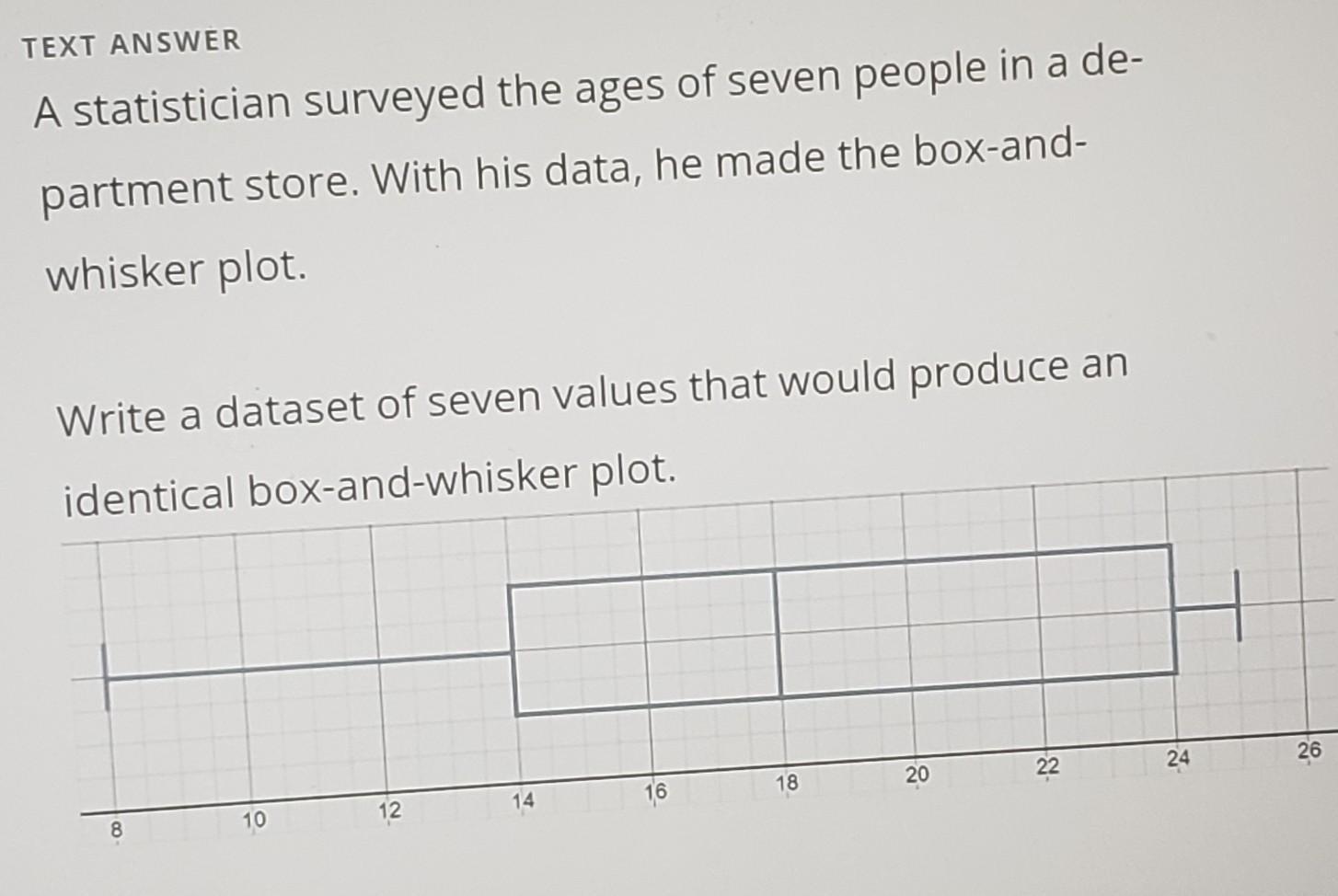
The data-set of seven values with the same box and whisker plot is given as follows:
8, 14, 16, 18, 22, 24, 25.
What does a box and whisker plot shows?A box and whisker plots shows these five metrics from a data-set, listed and explained as follows:
The minimum non-outlier value.The 25th percentile, representing the value which 25% of the data-set is less than and 75% is greater than.The median, which is the middle value of the data-set, the value which 50% of the data-set is less than and 50% is greater than%.The 75th percentile, representing the value which 75% of the data-set is less than and 25% is greater than.The maximum non-outlier value.Considering the box plot for this problem, for a data-set of seven values, we have that:
The minimum value is of 8.The median of the first half is the second element, which is the first quartile of 14.The median is the fourth element, which is of 18.The median of the secodn half is the sixth element, which is the third quartile of 24.The maximum value is of 25.More can be learned about box plots at https://brainly.com/question/3473797
#SPJ1
Related Questions
In a recent survey of mobile phone ownership, 73.4% of the respondents said they own Android Phones, while 21.8% indicated they own both Android and IOS phones, and 80.1% said they own at least one of the two types of phones.
Define the events as
A = Owning a Maytag appliance
I = Owning a GE appliance
a)
What is the probability that a respondent owns an IOS phone?
b)
Given that a respondent owns an Android Phone, what is the probability that the respondent also owns an IOS phone?
c)
Are events "A" and "I" mutually exclusive? Why or why not? Use probabilities to explain.
d)
Are the two events "A" and "I" independent? Why or why not? Use probabilities to explain.
Answers
Let's define the events as follows:
A = Owning a Maytag appliance (Maytag)
I = Owning a GE appliance (GE)
a) To find the probability that a respondent owns an iOS phone, we need to subtract the probability of owning both Android and iOS phones from the probability of owning only iOS phones.
P(IOS) = P(Android and IOS) + P(IOS only)
= 21.8% + (73.4% - 21.8%)
= 21.8% + 51.6%
= 73.4%
Therefore, the probability that a respondent owns an iOS phone is 73.4%.
b) To find the probability that a respondent, given that they own an Android phone, also owns an iOS phone, we can use conditional probability.
P(IOS | Android) = P(Android and IOS) / P(Android)
= 21.8% / 73.4%
= 0.297
Therefore, the probability that a respondent, given that they own an Android phone, also owns an iOS phone is 0.297 or 29.7%.
c) Events A (Maytag) and I (GE) are considered mutually exclusive if they cannot occur together. In this case, we need to check if owning a Maytag appliance and owning a GE appliance can happen simultaneously.
Since the problem statement does not provide any information about the relationship between owning a Maytag appliance and owning a GE appliance, we cannot determine their mutual exclusivity solely based on the given probabilities. We would need additional information to make a definitive conclusion.
d) Two events A (Maytag) and I (GE) are considered independent if the occurrence of one event does not affect the probability of the other event occurring.
To determine if events A and I are independent, we need to compare the joint probability of both events occurring with the product of their individual probabilities.
P(A and I) = P(Maytag and GE) = 0 (not provided)
P(A) = P(Maytag) = 0 (not provided)
P(I) = P(GE) = 0 (not provided)
Without knowing the joint probability of owning both a Maytag and a GE appliance or the individual probabilities of owning each appliance, we cannot determine if events A and I are independent.
In summary, based on the given information, we cannot definitively determine whether events A (Maytag) and I (GE) are mutually exclusive or independent without additional information.
Learn more about mutually exclusive here:
https://brainly.com/question/12947901
#SPJ11
Q.4 What is the difference between price floors and price ceiling? Give example and illustrate graphically in support of your answer.
Answers
A price floor is a law that limits the minimum price at which a good, service, or factor of production can be sold while a price ceiling is a regulation that limits the maximum price at which a good, service, or factor of production can be sold
Price floors are commonly implemented to support producers, while price ceilings are typically put in place to protect consumers from higher prices that might result from shortages or monopolies.
Example of Price Floor:Agricultural subsidies are a common example of price floors. Government price floors ensure that farmers receive a minimum price for their crops.
If the market price of wheat falls below the government-established price floor, the government may buy the excess supply at the guaranteed price, ensuring that farmers are able to make a profit. If there is a price floor, the minimum price is set above the equilibrium price.
Learn more about price ceiling at:
https://brainly.com/question/2562066
#SPJ11
f: {0, 1}³ → {0, 1}³f(x) is obtained by replacing the last bit from x with is f(110)? select all the strings in the range of f:
Answers
The range of the function f is the set of all possible outputs or images. Therefore, the range of f is {000, 001, 010, 011, 100, 101, 111}.
Thus ,the range of f is {000, 001, 010, 011, 100, 101, 111}.
Thus, the strings in the range of f are:000, 001, 010, 011, 100, 101, 111.
All the above strings are in the range of f.
Select all the strings in the range of f:
To find the range of the function f, we substitute each element of the domain into the function f and get its corresponding output. f(110) means we replace the last bit of 110 i.e., we replace the last bit of 6 in binary which is 110, with either 0 or 1. Let's take 0 as the replacement bit.
Thus, f(110) = 100, which means the last bit of 110 is replaced with 0.
Now, let's find the range of the function f.
To find the range, we substitute each element of the domain into the function f and get its corresponding output.
[tex]f(000) = 000f(001) = 001f(010) = 010f(011) = 011f(100) = 100f(101) = 101f(110) = 100f(111) = 111[/tex]
The range of the function f is the set of all possible outputs or images. Therefore, the range of f is {000, 001, 010, 011, 100, 101, 111}.
Thus, the strings in the range of f are:000, 001, 010, 011, 100, 101, 111.
All the above strings are in the range of f.
To know more about function visit:
https://brainly.com/question/30721594
#SPJ11
The strings in the range of f are: 000, 001, 010, 011, 100, 101, 111
Given f: {0, 1}³ → {0, 1}³, f(x) is obtained by replacing the last bit from x with x.
We have to find the value of f(110) and select all the strings in the range of f.
To find f(110), we replace the last bit of 110 with itself.
So we get, f(110) = 111Similarly,
we can get all the values in the range of f by replacing the last bit of the input with itself: f(000) = 000f(001) = 001f(010) = 010f(011) = 011f(100) = 100f(101) = 101f(110) = 111f(111) = 111
Therefore, the strings in the range of f are: 000, 001, 010, 011, 100, 101, 111.
To know more about obtained visit :-
https://brainly.com/question/26761555
#SPJ11
Study on 15 students of Class-9 revealed that they spend on average 174 minutes per day on watching online videos which has a standard deviation of 18 minutes. The same for 15 students of Class-10 is 118 minutes with a standard deviation of 45 minutes. Determine, at a 0.01 significance level, whether the mean time spent by the Class-9 students are different from that of the Class-10 students. [Hint: Determine sample 1 & 2 first. Check whether to use Z or t.]
Answers
An average of 174 minutes per day with a standard deviation of 18 minutes, while Class-10 students spent an average of 118 minutes with a standard deviation of 45 minutes.
To compare the means of two independent samples, a hypothesis test can be performed using either the Z-test or t-test, depending on the sample size and whether the population standard deviations are known. In this case, the sample sizes are both 15, which is relatively small. Since the population standard deviations are unknown, the appropriate test to use is the two-sample t-test.
The null hypothesis (H0) states that the mean time spent by Class-9 students is equal to the mean time spent by Class-10 students. The alternative hypothesis (Ha) states that the means are different. By conducting the two-sample t-test and comparing the t-value to the critical value at a 0.01 significance level (using the appropriate degrees of freedom), we can determine whether to reject or fail to reject the null hypothesis.
If the calculated t-value falls within the rejection region (beyond the critical value), we reject the null hypothesis and conclude that the mean time spent by Class-9 students differs significantly from that of Class-10 students. On the other hand, if the calculated t-value falls within the non-rejection region, we fail to reject the null hypothesis, indicating that there is not enough evidence to conclude a significant difference between the mean times spent by the two classes.
The actual calculations and final decision regarding the rejection or acceptance of the null hypothesis can be done using statistical software or tables.
Learn more about standard deviation here:
https://brainly.com/question/29115611
#SPJ11
4) In this question we work in a propositional language with propositional variables P₁, Pn only. (i) (a) What is a valuation and what is a truth function for this propositional lan- guage? (b) Show there are 2" valuations. (c) How many truth functions are there? [8 marks] (ii) Demonstrate using examples how a propositional formula o gives rise to truth function fo. Between them, your examples should use all the connectives A, V, →→, ¬, and ↔. [6 marks] (iii) Prove that not every truth function is of the form fo for a propositional formula constructed only using the connectives and V. [6 marks]
Answers
The truth function for a propositional language represents the relationship between all of the propositional variables (including the negation of those variables), and the truth values they take.(b) Show there are 2^n valuations.
There are 16 possible truth functions for this propositional language. To see why, consider that each of the [tex]2^2 = 4[/tex] valuations can be mapped to one of two truth values (true or false), and there are [tex]2^2[/tex] possible combinations of truth values. So, there are [tex]2^(2^2) = 16[/tex] possible truth functions.
Demonstrate using examples how a propositional formula o gives rise to truth function fo. In order to create a truth function, we need to specify which propositional variable assignments are true and which are false. We will use the following examples: Let [tex]o = P1 V Pn1[/tex].
To know more about truth visit:
https://brainly.com/question/30671942
#SPJ11
tarting with the given fact that the type 1 improper integral ∫ [infinity] 1 dx converges to 1 1 xp p−1 when p > 1 , use the substitution u = 1x to determine the values of p for which the type 2 improper integral ∫ 1 1 dx converges and determine the value of the integral for those values of p
Answers
The given problem involves determining the values of p for which the type 2 improper integral ∫ 1 to 1 dx converges using the substitution u = 1/x.
We start with the type 2 improper integral ∫ 1 to 1 dx. This integral is not defined since the limits of integration are the same, resulting in an interval of zero length. However, by applying the substitution u = 1/x, we can transform the integral into a new form.
Substituting x = 1/u, we have dx = -1/u² du. The limits of integration also change: when x = 1, u = 1/1 = 1, and when x = 1, u = 1/1 = 1. Therefore, the new integral becomes ∫ 1 to 1 (-1/u²) du.
Simplifying, we have ∫ 1 to 1 (-1/u²) du = -∫ 1 to 1 du. Since the limits of integration are the same, the value of this integral is zero. Thus, the type 2 improper integral ∫ 1 to 1 dx converges to zero for all values of p, as it reduces to the constant zero after the substitution.
Learn more about integrals here: brainly.com/question/4615818
#SPJ11
Let x and y be vectors for comparison: x = (7, 14) and y = (11, 3). Compute the cosine similarity between the two vectors. Round the result to two decimal places.
Answers
The cosine similarity between vectors x = (7, 14) and y = (11, 3) is approximately 0.68 when rounded to two decimal places.
To compute the cosine similarity, we follow these steps:
Calculate the dot product of the two vectors: x · y = (7 * 11) + (14 * 3) = 77 + 42 = 119.
Compute the magnitude of vector x: ||x|| = sqrt((7^2) + (14^2)) = sqrt(49 + 196) = sqrt(245) ≈ 15.65.
Compute the magnitude of vector y: ||y|| = sqrt((11^2) + (3^2)) = sqrt(121 + 9) = sqrt(130) ≈ 11.40.
Multiply the magnitudes of the vectors: ||x|| * ||y|| = 15.65 * 11.40 ≈ 178.71.
Divide the dot product of the vectors by the product of their magnitudes: cosine similarity = x · y / (||x|| * ||y||) = 119 / 178.71 ≈ 0.6668.
Rounding this value to two decimal places, we get a cosine similarity of approximately 0.68.
To learn more about dot product click here:
brainly.com/question/23477017
#SPJ11
The cosine similarity between vectors x = (7, 14) and y = (11, 3) is approximately 0.68 when rounded to two decimal places.
To compute the cosine similarity, we follow these steps:
Calculate the dot product of the two vectors: x · y = (7 * 11) + (14 * 3) = 77 + 42 = 119.
Compute the magnitude of vector x: ||x|| = sqrt((7^2) + (14^2)) = sqrt(49 + 196) = sqrt(245) ≈ 15.65.
Compute the magnitude of vector y: ||y|| = sqrt((11^2) + (3^2)) = sqrt(121 + 9) = sqrt(130) ≈ 11.40.
Multiply the magnitudes of the vectors: ||x|| * ||y|| = 15.65 * 11.40 ≈ 178.71.
Divide the dot product of the vectors by the product of their magnitudes: cosine similarity = x · y / (||x|| * ||y||) = 119 / 178.71 ≈ 0.6668.
Rounding this value to two decimal places, we get a cosine similarity of approximately 0.68.
To learn more about dot product click here:
brainly.com/question/23477017
#SPJ11
"is
my answer clear ?(if not please explain)
Using a Xbar Shewhart Control Chart with n= 4, the probability ß of not detecting a mismatch (mean shift) of a 2-standard deviation on the first subsequent sample is between: (It is better to use OC curves"
a.0.1 and 0.2
b.0.3 and 0.4
c.0.5 and 0.6
d.0.8 and 0.9
Answers
Using an Xbar Shewhart Control Chart with a sample size of n = 4, the probability ß of not detecting a mean shift of 2 standard deviations on the first subsequent sample falls between the range of options .
To determine the range of ß, which represents the probability of not detecting a mean shift, we can refer to the Operating Characteristic (OC) curves associated with the Xbar Shewhart Control Chart. These curves illustrate the probability of detecting a mean shift for different shift sizes and sample sizes.
Since the sample size, in this case, is n = 4, we can consult the OC curve specific to this sample size. Based on the properties of the control chart and the OC curve, we find that the range of ß for a mean shift of 2 standard deviations on the first subsequent sample is between the provided options (a) 0.1 and 0.2, (b) 0.3 and 0.4, (c) 0.5 and 0.6, or (d) 0.8 and 0.9.
The exact value of ß within this range depends on the specific characteristics of the control chart and the underlying process.
Learn more about standard deviation here: brainly.com/question/29115611
#SPJ11
The number of visitors P to a website in a given week over a 1-year period is given by P(t) = 117 + (t-90) e 0.02t, where t is the week and 1 ≤t≤ 52. a) Over what interval of time during the 1-year period is the number of visitors decreasing? b) Over what interval of time during the 1-year period is the number of visitors increasing? c) Find the critical point, and interpret its meaning. a) The number of visitors is decreasing over the interval (Simplify your answer. Type integers or decimals rounded to three decimal places as needed. Type your answer in interval notation.)
Answers
If the number of visitors P to a website in a given week over a 1-year period is given by [tex]P(t) = 117 + (t-90) e^{0.02t}[/tex], where t is the week and 1 ≤t≤ 52, the interval of time during the 1-year period the number of visitors decreases is 1 ≤ t < 40, the interval of time during the 1-year period the number of visitors increases is 40 < t ≤ 52 and the critical point is t=40 and its interpretation is that it corresponds to the week during which the number of visitors is neither increasing nor decreasing.
(a) To find the interval of time during the 1-year period the number of visitors decreases, follow these steps:
To find the interval over which the number of visitors is decreasing, we need to find the interval of t over which the derivative of the function is negative. Taking the first derivative of P(t), we get P'(t) = [tex]\frac{d}{dt}[117 + (t-90) e^{0.02t}]\\ = 0 + (1) e^{0.02t} + (t-90)(e^{0.02t})(0.02)\\ = e^{0.02t} + 0.02(t-90)e^{0.02t}\\ = e^{0.02t}[1 + 0.02(t-90)][/tex]. On putting P'(t)=0, we get t=40. For t < 40, 1 + 0.02(t-90) < 0, since (t-90) is negative and for t > 40, 1 + 0.02(t-90) > 0, since (t-90) is positive. Therefore, the number of visitors is decreasing for 1 ≤ t < 40.(b) To find the interval of time during the 1-year period the number of visitors increases, follow these steps:
To find the interval over which the number of visitors is increasing, we need to find the interval of t over which the derivative of the function is positive. Taking the first derivative of P(t), we get P'(t) = [tex]\frac{d}{dt}[117 + (t-90) e^{0.02t}]\\ = 0 + (1) e^{0.02t} + (t-90)(e^{0.02t})(0.02)\\ = e^{0.02t} + 0.02(t-90)e^{0.02t}\\ = e^{0.02t}[1 + 0.02(t-90)][/tex]. On putting P'(t)=0, we get t=40. For t < 40, 1 + 0.02(t-90) < 0, since (t-90) is negative and for t > 40, 1 + 0.02(t-90) > 0, since (t-90) is positive. Therefore, the number of visitors is increasing for 40 < t ≤ 52.(c) To find the critical point and interpret its meaning, follow these steps:
The critical point of a function is the point at which the derivative of the function is zero or undefined. Taking the first derivative of P(t), we get P'(t) = [tex]\frac{d}{dt}[117 + (t-90) e^{0.02t}]\\ = 0 + (1) e^{0.02t} + (t-90)(e^{0.02t})(0.02)\\ = e^{0.02t} + 0.02(t-90)e^{0.02t}\\ = e^{0.02t}[1 + 0.02(t-90)][/tex]. On putting P'(t)=0, we get t=40.The interpretation of the critical point is that it corresponds to the week during which the number of visitors is neither increasing nor decreasing.Learn more about critical point:
brainly.com/question/29144288
#SPJ11
Find an equation of the plane perpendicular to the line where plane 4x-3y +27=5 and plane 3x+2y=Z+11=0 meet after passing a point (6,2,-1).
Answers
To find an equation of the plane perpendicular to the line of intersection between the planes 4x - 3y + 27 = 5 and 3x + 2y + z + 11 = 0, passing through the point (6, 2, -1),
The normal vector of the first plane is (4, -3, 0), and the normal vector of the second plane is (3, 2, 1). Taking their cross product, we get the direction vector of the line as (3, -12, 17). This vector represents the direction in which the line extends. Next, using the point (6, 2, -1),
we can substitute its coordinates into the general equation of a plane, which is ax + by + cz = d, to determine the values of a, b, c, and d. Substituting the point coordinates, we obtain 3(x - 6) - 12(y - 2) + 17(z + 1) = 0. This equation represents the plane perpendicular to the line of intersection between the given planes, passing through the point (6, 2, -1).
To learn more about cross product click here :
brainly.com/question/29097076
#SPJ11
To study the effect of temperature on yield in a chemical process, five batches were produced at each of three temperature levels. The results follow. Temperature 50°C 60°C 70°C 31 34 27 21 35 32 33 38 32 36 27 34 29 31 35 a. Construct an analysis of variance table (to 2 decimals but p-value to 4 decimals, if necessary). Source of Variation Sum of Squares Degrees of Freedom Mean Square p-value F 2 Treatments 19.67 236 12 Error 14 Total b. Use a .05 level of significance to test whether the temperature level has an effect on the mean yield of the process. Calculate the value of the test statistic (to 2 decimals). The p-value is greater than .10 What is your conclusion? Do not reject the assumption that the mean yields for the three temperatures are equal
Answers
To study the effect of temperature on yield in a chemical process, an analysis of variance (ANOVA) was conducted on the data. The results indicate that the p-value is greater than 0.10, suggesting that there is no significant effect of temperature on the mean yield of the process. Therefore, we do not have enough evidence to reject the assumption that the mean yields for the three temperature levels (50°C, 60°C, and 70°C) are equal.
The main answer states that the assumption of equal mean yields for the three temperature levels cannot be rejected. This means that the temperature does not have a significant effect on the yield of the chemical process.
In the ANOVA table, we have two sources of variation: treatments and error. The treatments refer to the different temperature levels (50°C, 60°C, and 70°C), and the error represents the variability within each temperature level. The sum of squares (SS) and degrees of freedom (DF) for each source of variation are given. The mean square (MS) is obtained by dividing the sum of squares by the degrees of freedom.
To test the hypothesis of whether temperature has an effect on the mean yield, we compare the F statistic, which is the ratio of the mean square for treatments to the mean square for error. The p-value is then calculated based on the F statistic. In this case, the p-value is greater than 0.10, which indicates that there is no significant difference in mean yields among the three temperature levels.
In conclusion, based on the analysis, we do not have sufficient evidence to conclude that the temperature has a significant effect on the yield of the chemical process.
Learn more about ANOVA
brainly.com/question/32576120
#SPJ11
Solve the system. Give answers (x, y, z)
x-5y+4z= -5
2x+5y-z= 14
-4x+ 5y-3z= -8
Answers
Thus, the answer to the given system is (-59, -8, -113).
To solve the given system of equations, we can use the elimination method. First, we will use the first equation to eliminate x from the second and third equations. Then we will use the second equation to eliminate y from the third equation.
Here are the steps:
Step 1: Use the first equation to eliminate x from the second and third equations2x + 5y - z = 14 (equation 2)x - 5y + 4z = -5 (equation 1)Multiplying equation 1 by 2 and adding the resulting equation to equation 2,
we get:2x - 10y + 8z = -10+2x + 5y - z = 14_
7y + 7z = 4 (new equation)
4x - 5y + 3z = 8 (equation 3)
Multiplying equation 1 by 4 and adding the resulting equation to equation 3,
we get:4x - 20y + 16z = -20+(-4x) + 5y - 3z = -8
-15y + 13z = 12 (new equation)
So now we have two new equations:
7y + 7z = 4-15y + 13z = 12
Step 2: Use the second equation to eliminate y from the third equation.
7y + 7z = 4 (new equation)
Multiplying equation 2 by 7 and adding the resulting equation to the new equation, we get:
2x + 5y - z = 14 (equation 2)
49y + 49z = 98+7y + 7z = 456y + 56z = 102 (new equation)
4x - 5y + 3z = 8 (equation 3)
Multiplying equation 2 by 5 and adding the resulting equation to equation 3,
we get:4x + 25y - 5z = 704x - 5y + 3z = 8
20y - 2z = 62 (new equation)So now we have two new equations:
56y + 56z = 10220
y - 2z = 62
We can use the second equation to solve for y:
y = (62 + 2z)/20y = (31 + z)/10
Substituting this value of y into the first new equation, we get:
56(31 + z)/10 + 56z = 102560 + 56z + 560z
= 10204z = -452z
= -113Substituting this value of z into the expression for y, we get:
y = (31 - 113)/10y = -8
Substituting these values of x, y, and z into any of the original equations, we can check that they satisfy the system.
For example:2x + 5y - z = 14 (equation 2)2x + 5(-8) - (-113) = 14x - 40 + 113 = 14x + 73 = 14x = -59So the solutions are:
x = -59y = -8z = -113
Therefore, the solution is (-59, -8, -113).
Thus, the answer to the given system is (-59, -8, -113).
To know more about System visit:
https://brainly.com/question/29122349
#SPJ11
4. Use Laplace transform to solve the initial value problem: y"(t) + 2y(t) = g(t); y(0) = 0, y'(0) = 2; where 2t 0
Answers
We can conclude that the solution to the initial value problem using Laplace transform is:y(t) = 1/√2 sin(√2t) - t*sin(t) for t > 0.
The Laplace transform is one of the most essential and widely used transforms in mathematics and engineering. It converts functions from the time domain into the frequency domain, where they may be easier to analyze mathematically.
Laplace transform helps solve differential equations in the same manner that the Fourier transform simplifies linear and time-invariant systems.
The initial value problem:y″(t) + 2y(t) = g(t); y(0) = 0, y′(0) = 2;
where g(t) = 2t; for t > 0.
It means that y'' + 2y = 2t, y(0) = 0, y'(0) = 2.
Using the Laplace Transform:
Taking Laplace Transform of both sides
y''(t) + 2y(t) = g(t)
Taking Laplace Transform of both sides using linearity rule
L{y''(t)} + 2L{y(t)} = L{g(t)}
L{y''(t)} = s²Y(s) - sy(0) - y'(0)
where Y(s) is the Laplace Transform of y(t)
L{y''(t)} = s²Y(s) - sy(0) - y'(0)L{y''(t)} + 2
L{y(t)} = L{g(t)}
⇒ s²Y(s) - sy(0) - y'(0) + 2Y(s) = L{g(t)}
Substituting the initial conditions: y(0) = 0,
y'(0) = 2Y(s) = {L{g(t)} + sy(0) + y'(0)}/(s²+ 2)
= (2/s²+ 2) + {L{2t}}/(s²+ 2)
Taking the Laplace Transform of
g(t) = 2tL{2t}
= 2 * {1/s²}
= 2/s²
Therefore
Y(s) = (2/s²+ 2) + 2/s²(s²+ 2)
The partial fraction is written as:
Y(s) = A/(s²+ 2) + B/(s²)
⇒ 2/s²(s²+ 2) = A/(s²+ 2) + B/(s²)
By solving for A and B, we getA = 1, B = -1
Hence,
Y(s) = 1/(s²+ 2) + (-1/s²)L-1
{Y(s)} = L-1 {1/(s²+ 2)} - L-1 {1/s²}L-1 {1/(s²+ 2)}
= 1/√2 sin(√2t)L-1 {1/s²}
= t
Hence the solution of the initial value problem:
y(t) = 1/√2 sin(√2t) - t*sin(t) for t > 0.
Know more about the Laplace transform
https://brainly.com/question/29583725
#SPJ11
The lifetime of a cellular phone is uniformly distributed with a minimum lifetime of 6 months and a maximum lifetime of 40 months. [4] a) What is the probability that a particular cell phone will last between 10 and 15 months? Sketch probability distribution as well. b) What is the probability that a cell phone will less than 12 months? Sketch the probability distribution as well
Answers
The required answers are:
a) The probability that a particular cell phone will last between 10 and 15 months is approximately 0.1471.
b) The probability that a cell phone will last less than 12 months is approximately 0.1765.
a) To find the probability that a cell phone will last between 10 and 15 months, we need to calculate the proportion of the total range of the distribution that falls within this interval. Since the lifetime of the phone is uniformly distributed, the probability can be determined by finding the width of the interval (15 - 10 = 5) and dividing it by the total range (40 - 6 = 34). Therefore, the probability is 5/34, which simplifies to approximately 0.1471.
To sketch the probability distribution, we can draw a rectangular bar graph where the x-axis represents the lifetime of the cell phone and the y-axis represents the probability density. The graph will show a constant height of 1/34 for the interval from 6 to 40 months, since the distribution is uniform.
b) To find the probability that a cell phone will last less than 12 months, we need to calculate the proportion of the total range of the distribution that is less than 12. Since the distribution is uniform, the probability is equal to the width of the interval from 6 to 12 (12 - 6 = 6) divided by the total range (40 - 6 = 34). Therefore, the probability is 6/34, which simplifies to approximately 0.1765.
To sketch the probability distribution, the graph will show a rectangular bar with a height of 6/34 from 6 to 12 months and a constant height of 1/34 for the interval from 12 to 40 months.
These sketches represent the probability distribution for the lifetime of a cellular phone with a minimum of 6 months and a maximum of 40 months.
Hence, the required answers are:
a) The probability that a particular cell phone will last between 10 and 15 months is approximately 0.1471.
b) The probability that a cell phone will last less than 12 months is approximately 0.1765.
Learn more about probability distributions here:
https://brainly.com/question/29062095
#SPJ12
A region is enclosed by the equations below. Find the volume of the solid obtained by rotating the region about the line y = 1.
X=y^8 y = 1, x=20
Answers
The volume of the solid obtained by rotating the region enclosed by the equations x = y^8, y = 1, and x = 20 about the line y = 1 is π/45 cubic units.
To find the volume, we use the method of cylindrical shells. The region is bounded by the curves y = 1 and x = y^8, extending from y = 0 to y = 1. We set up the integral ∫[0,1] 2π(y - 1)(y^8) * dy and evaluate it to obtain the volume. Integrating term by term, we get 2π [(1/10)y^10 - (1/9)y^9]. Evaluating this expression from 0 to 1, we find the volume to be -π/45 cubic units.
The volume is negative because the region lies below the axis of rotation (y = 1). The integral represents the difference between the volume of the solid and the volume of the empty space below the axis of rotation. Therefore, we take the absolute value of the result to obtain the positive volume of the solid, which is π/45 cubic units.
To learn more about volume click here
brainly.com/question/1578538
#SPJ11
Write a negation of the statement.
Some athletes are musicians.
(Points : 2)
All athletes are not musicians.
Some athletes are not musicians.
All athletes are musicians.
No athletes are musicians.
Chose from the above four which is the correct answer.
Answers
The negation of the statement "Some athletes are musicians" is "Some athletes are not musicians.
A negation of a statement is the opposite of the original statement. In this case, the original statement is
"Some athletes are musicians."To negate this statement, we need to say something that is the opposite of
"Some athletes are musicians."
The opposite of "Some" is "Some are not," so the negation is "Some athletes are not musicians."
Summary:Therefore, the negation of the statement "Some athletes are musicians" is "Some athletes are not musicians."
Learn more about negation click here
https://brainly.com/question/22621136
#SPJ11
Q.1 A population of 750 healthy females was followed for the development of heart disease for 25 years. 75 of these female developed heart at 7 years, then another 50 developed it at 15 years, and 10 died from other causes at the end of observation period. Another 55 females were lost to follow up at 3 years. The remainder were followed for the entire period. Calculate the:
Prevalence of heart disease at the end of 7 years in this population
Cumulative incidence of heart disease in this population
Incidence density/incidence rate of heart disease in this population
Which measure (cumulative incidence or incidence density/incidence rate) will be most appropriate for interpreting findings? Why?
Q.2 Assume that there were 805 new cases of legionnaires disease was diagnosed among residents in Boston, MA and 800 new cases were diagnosed in Albuquerque, NM in 2016. Based on these data is it accurate to conclude that the incidence of legionnaire’s disease is higher in Boston than Albuquerque? Why or why not?
Population and Number of Deaths by Age for Communities X and Y
Community X
Community Y
Age (years)
Population
Deaths
Death Rate (per 1,000)
Population
Deaths
Death Rate (per 1,000)
Under 1
1,000
25
5,000
150
1-4
3,000
3
20,000
10
15-34
6,000
6
35,000
35
35-54
13,000
75
17,000
85
55-64
7,000
105
8,000
250
65 and older
20,000
1,600
15,000
1,350
All ages
50,000
1,814
100,000
1,880
Calculate and compare the overall crude death rates for Communities X and Y respectively.
Calculate and compare the age-specific death rates of Communities X and Y. What can you deduce from this? Are these comparisons different from the crude rates?
Standard Population by Age and Age-specific Mortality Rates for Communities N and Q
Age (years)
Standard Population for (N and Q)
Mortality Rate in N (per 1,000)
Expected Cases at N’s rates
Mortality Rate in Q (per 1,000)
Expected Cases at Q’s rates
Under 1
9,500
25.0
35.0
1-4
55,000
7.0
3.0
15-34
75,000
5.0
10.0
35-54
65,000
25.0
15.0
55-64
30,000
3.0
7.0
65 and older
35,000
75.0
80.0
All ages
269,500
42.5
21.3
Using the appropriate adjustment method, calculate the overall adjusted mortality rates for Communities N and Q respectively with the given standard population. Indicate which adjustment method was used.
Can you calculate the SMR for Communities N and Q from the information provided? Explain the reason for your answer.
Answers
Prevalence of heart disease at the end of 7 years in this population:
The prevalence of heart disease at the end of 7 years can be calculated by summing the number of females who developed heart disease at 7 years and the number of females who already had heart disease at the beginning of the observation period, and dividing it by the total population.
Prevalence at 7 years = (Number of females with heart disease at 7 years + Number of females with heart disease at the beginning of the observation period) / Total population
Prevalence at 7 years = (75 + 10) / 750
Prevalence at 7 years = 85 / 750
Prevalence at 7 years = 0.1133 or 11.33%
Cumulative incidence of heart disease in this population:
The cumulative incidence of heart disease can be calculated by dividing the number of new cases of heart disease over the observation period by the total population.
Cumulative incidence = (Number of new cases of heart disease) / Total population
Cumulative incidence = (75 + 50) / 750
Cumulative incidence = 125 / 750
Cumulative incidence = 0.1667 or 16.67%
Incidence density/incidence rate of heart disease in this population:
The incidence density or incidence rate of heart disease can be calculated by dividing the number of new cases of heart disease by the person-time at risk. Person-time at risk is the sum of the time each individual was under observation.
Incidence rate = (Number of new cases of heart disease) / Person-time at risk
In this case, we are not provided with the person-time at risk, so we cannot calculate the incidence density or incidence rate.
Which measure (cumulative incidence or incidence density/incidence rate) will be most appropriate for interpreting findings? Why?
The cumulative incidence is more appropriate for interpreting findings in this case. Cumulative incidence provides the proportion or percentage of individuals who developed the disease within a specific time period (in this case, over the 25-year observation period).
It gives a measure of the disease burden and helps understand the overall risk of developing the disease in the population.
To determine if the incidence of legionnaire's disease is higher in Boston than Albuquerque, we need to consider the population size of each city. Comparing the number of cases alone does not provide a fair comparison since the population sizes are different.
To determine the incidence rate, we need to know the population at risk in each city. Without information about the population size and the person-time at risk, we cannot accurately calculate the incidence rate.
Therefore, we cannot conclude whether the incidence of legionnaire's disease is higher in Boston than Albuquerque based solely on the number of cases reported.
Additional information about the population sizes and person-time at risk would be necessary to make a valid comparison of the incidence rates between the two cities.
To know more about Prevalence refer here:
https://brainly.com/question/30539295#
#SPJ11
BASIC PROBLEMS WITH ANSWERS
7.1. A real-valued signal x(t) is known to be uniquely determined by its samples when the sampling frequency is w, = 10,000. For what values of w is X(jw) guaranteed to be zero?
7.2. A continuous-time signal x(t) is obtained at the output of an ideal lowpass filter with cutoff frequency we = 1,000╥. If impulse-train sampling is performed on x(t), which of the following sampling periods would guarantee that x(t) can be recovered from its sampled version using an appropriate lowpass filter?
(a) T = 0.5 × 10-3
(b) T = 2 x 10-3
(c) T = 10-4
Answers
7.1. X(jw) is guaranteed to be zero for values of w less than the Nyquist frequency, which is half the sampling frequency of x(t) (10,000).
7.2. All three sampling periods (T) provided (0.5 × 10⁻³, 2 × 10⁻³, 10⁻⁴) would allow the recovery of x(t) from its sampled version using an appropriate lowpass filter.
7.1. The values of w for which X(jw) is guaranteed to be zero are the frequencies at which the Fourier Transform of the signal x(t) has zero magnitude. In this case, x(t) is uniquely determined by its samples when the sampling frequency is wₛ = 10,000.
This implies that the Nyquist frequency, which is half of the sampling frequency, must be greater than the highest frequency component of x(t) to avoid aliasing. Therefore, the Nyquist frequency is w_N = wₛ/2 = 5,000. For X(jw) to be zero, the frequency w must satisfy the condition w < w_N. So, for values of w less than 5,000, X(jw) is guaranteed to be zero.
7.2. To recover a continuous-time signal x(t) from its sampled version using an appropriate lowpass filter, the sampling theorem states that the sampling frequency must be at least twice the maximum frequency component of x(t). In this case, the cutoff frequency of the ideal lowpass filter is wₑ = 1,000π.
The maximum frequency component of x(t) can be assumed to be the same as the cutoff frequency. So, according to the sampling theorem, the sampling frequency wₛ must be at least twice wₑ. Therefore, we can calculate the minimum sampling period Tₘ by taking the reciprocal of twice the cutoff frequency: Tₘ = 1 / (2wₑ). Let's calculate the values for the given options:
(a) T = 0.5 × 10⁻³: Tₘ = 1 / (2 × 1000π) = 1 / (2000π) ≈ 0.000159 ≈ 1.59 × 10⁻⁴
(b) T = 2 × 10⁻³: Tₘ = 1 / (2 × 1000π) = 1 / (2000π) ≈ 0.000159 ≈ 1.59 × 10⁻⁴
(c) T = 10⁻⁴: Tₘ = 1 / (2 × 1000π) = 1 / (2000π) ≈ 0.000159 ≈ 1.59 × 10⁻⁴
Based on the calculations, all three sampling periods (T) would guarantee that x(t) can be recovered from its sampled version using an appropriate lowpass filter.
To know more about the Nyquist-Shannon sampling theorem, refer here: https://brainly.com/question/31735568#
#SPJ11
Create a real-life problem that can be modelled by an acute triangle. Then describe the problem. sketch the situation in your problem, and explain what must be done to solve it.
Answers
Real-Life Problem Determining the optimal angle for launching a rocket into space to maximize altitude.
What is a real-life application that can be modeled by an acute triangle and requires the determination of the optimal angle for achieving a specific outcome?Real-Life Problem: Determining the Optimal Angle for Launching a Rocket into Space
Description: A space agency is planning to launch a rocket into space. They need to determine the optimal angle at which the rocket should be launched to achieve the maximum altitude. This problem can be modeled by an acute triangle.
Situation Sketch: Imagine a rocket sitting on a launchpad on the ground. The launchpad represents one vertex of the acute triangle. The base of the triangle is the horizontal ground, and the other two vertices represent the rocket's initial position and the point where it reaches its maximum altitude.
Explanation: To solve the problem, the space agency needs to determine the optimal launch angle, which is the angle between the rocket's initial position and the ground. The goal is to find the angle that maximizes the rocket's altitude.
To solve the problem, the space agency can use principles from physics, specifically projectile motion. They need to consider factors such as the rocket's initial velocity, the force of gravity, air resistance, and the rocket's mass.
Using mathematical equations and calculations, the agency can determine the launch angle that will result in the rocket reaching the maximum altitude.
This may involve analyzing the rocket's trajectory, calculating the range and maximum height based on different launch angles, and optimizing the launch angle for the desired altitude.
By solving the equations and considering other factors such as safety, fuel efficiency, and payload requirements, the space agency can determine the optimal launch angle and successfully launch the rocket into space, maximizing its altitude and achieving the mission's objectives.
Learn more about Real-Life Problem
brainly.com/question/31581175
#SPJ11
Find the root of x tan x = 0.5 which lies between x= 0.6, x= 0.7 by the Newton process. Three iterations are required
Answers
Using the Newton process, the root of the equation x tan x = 0.5, which lies between x = 0.6 and x = 0.7, can be found in three iterations. The approximate root obtained after three iterations is x ≈ 0.656.
The Newton process is an iterative method used to approximate the root of a function. In this case, we want to find the root of the equation x tan x = 0.5 within the interval (0.6, 0.7).
To begin, we need to choose an initial guess for the root. Let's take x₀ = 0.6. Then, we can use the following iteration formula:
xᵢ₊₁ = xᵢ - f(xᵢ)/f'(xᵢ)
where f(x) = x tan x - 0.5 and f'(x) is the derivative of f(x).
First Iteration:
Using x₀ = 0.6, we can calculate f(x₀) and f'(x₀). Evaluating f(x₀) gives:
f(0.6) = (0.6) tan(0.6) - 0.5 ≈ -0.017
To find f'(x₀), we differentiate f(x) with respect to x:
f'(x) = tan x + x sec² x
Evaluating f'(x₀) gives:
f'(0.6) = tan(0.6) + (0.6) sec²(0.6) ≈ 2.626
Using the iteration formula, we can now calculate x₁:
x₁ = 0.6 - (-0.017)/2.626 ≈ 0.607
Second Iteration:
Using the iteration formula, we calculate x₂:
x₂ = 0.607 - (-0.00063)/2.622 ≈ 0.607
Third Iteration:
Using the iteration formula, we calculate x₃:
x₃ = 0.607 - (-4.29e-07)/2.622 ≈ 0.606
After three iterations, we obtain an approximate root of x ≈ 0.606. This result lies between the initial bounds of x = 0.6 and x = 0.7, satisfying the given conditions.
To learn more about iterations.
Click here:brainly.com/question/14969794?
#SPJ11
Solve method of the Laplace transform. y" - 2y + 2y = e*. y(0) = 0. y'(0) = 1 by the Use the Laplace transform to solve the system of differential equations. dx = 4x - 2y + 2(t-1) dt dy = 3x - y + U(t-1) dt x (0) = 0, y(0) = Solve 3-1 -1 x + 2e¹ x=+,x=Xzx C Solve
Answers
To solve the given differential equation using the Laplace transform, we obtain the Laplace transform of the equation, solve for the Laplace transform of the unknown function, and then apply the inverse Laplace transform to find the solution. Similarly, for the system of differential equations.
Solving the differential equation y" - 2y + 2y = e*t with initial conditions y(0) = 0 and y'(0) = 1:
Taking the Laplace transform of the equation and using the initial conditions, we obtain the transformed equation in terms of the Laplace variable s. Then, solving for the Laplace transform of y, denoted as Y(s), we can find the inverse Laplace transform of Y(s) to obtain the solution y(t).
Solving the system of differential equations dx/dt = 4x - 2y + 2(t-1) and dy/dt = 3x - y + u(t-1) with initial conditions x(0) = 0 and y(0) = c:
Taking the Laplace transforms of the equations and using the initial conditions, we obtain the transformed equations in terms of the Laplace variables s and X(s) (transformed x) and Y(s) (transformed y). Solving for X(s) and Y(s), we can apply the inverse Laplace transform to find the solutions x(t) and y(t) in the time domain.
It's important to note that the specific calculations and algebraic manipulations involved in finding the Laplace transforms and applying the inverse Laplace transform depend on the given equations.
Learn more about inverse Laplace transform here:
https://brainly.com/question/30404106
#SPJ11
The temperature in a rectangular box is approximated by
T(x,y,z) = xyz(1-x)(3-y)(5-z),
0≤x≤1, 0≤y≤3, 0≤z≤5.
If a mosquito is located at (1, 2, 3), in which direction should it fly to cool off as rapidly as possible? as slowly as possible?
Answers
To determine the direction in which the mosquito should fly to cool off as rapidly as possible, we need to find the negative gradient of the temperature function T(x, y, z) = xyz(1-x)(3-y)(5-z) at the point (1, 2, 3). The negative gradient points in the direction of steepest descent, which represents the direction in which the temperature decreases most rapidly.
Let's calculate the negative gradient:
[tex]\nabla T(x, y, z) = \langle \frac{\partial T}{\partial x}, \frac{\partial T}{\partial y}, \frac{\partial T}{\partial z} \rangle[/tex]
To find ∂T/∂x, we differentiate T(x, y, z) with respect to x while treating y and z as constants:
[tex]\frac{\partial T}{\partial x} = yz(1-x)(3-y)(5-z) + xyz(3-y)(5-z)[/tex]
To find ∂T/∂y, we differentiate T(x, y, z) with respect to y while treating x and z as constants:
[tex]\frac{\partial T}{\partial y} = xz(1-x)(5-z) + xyz(1-x)(5-z)[/tex]
To find ∂T/∂z, we differentiate T(x, y, z) with respect to z while treating x and y as constants:
[tex]\frac{\partial T}{\partial z} = xy(1-x)(3-y) + xyz(1-x)(3-y)[/tex]
Now, let's evaluate the gradient at the point (1, 2, 3):
[tex]\nabla T(1, 2, 3) = \langle \frac{\partial T}{\partial x}(1, 2, 3), \frac{\partial T}{\partial y}(1, 2, 3), \frac{\partial T}{\partial z}(1, 2, 3) \rangle[/tex]
Substituting the values into the partial derivatives, we get:
[tex]\nabla T(1, 2, 3) = \langle 2(1-1)(3-2)(5-3) + 1(1)(3-2)(5-3), 1(1)(1-1)(5-3) + 1(1)(3-1)(5-3), 1(1)(3-2)(3-1) + 1(1)(3-2)(5-3) \rangle[/tex]
Simplifying, we have:
[tex]\nabla T(1, 2, 3) = \langle 0 + 1(1)(1)(2), 0 + 1(1)(2)(2), 0 + 1(1)(2)(2) \rangle\\\nabla T(1, 2, 3) = \langle 2, 4, 4 \rangle[/tex]
Therefore, the negative gradient at the point (1, 2, 3) is given by:
[tex]- \nabla T(1, 2, 3) = \langle -2, -4, -4 \rangle[/tex]
Hence, the mosquito should fly in the direction ⟨-2, -4, -4⟩ to cool off as rapidly as possible.
To determine the direction in which the mosquito should fly to cool off as slowly as possible, we consider the positive gradient, which points in the direction of steepest ascent. Thus, the mosquito should fly in the direction ⟨2, 4, 4⟩ to cool off as slowly as possible.
To know more about Gradient visit-
brainly.com/question/15301875
#SPJ11
The graph of f(x) = 5x2 is shifted 6 units to the left to obtain the graph of g(x). Which of the following equations best describes g(x)?
a g(x) = 5x2 + 6
b g(x) = 5(x − 6)2
c g(x) = 5(x + 6)2
d g(x) = 5x2 − 6
Answers
To shift the graph of the function f(x) = 5x^2 6 units to the left, we need to replace x with (x + 6) in the equation.
Therefore, the equation that best describes g(x) is:
g(x) = 5(x + 6)^2
So, the correct option is c) g(x) = 5(x + 6)^2.
A bearing of S 10degrees W would be written as a direction angle
with what measurement?
Answers
A bearing of S 10° W would be written as a direction angle, a bearing of S 10 degrees W would be written as a direction angle of N 80° W.
A bearing of S 10° W would be written as a direction angle with what measurement?In surveying and navigation, bearings are a way to describe the direction of a straight line between two points. The bearing of a line is the angle between the line and the north-south direction. Bearings can be expressed in two ways: one is the bearing angle and the other is the direction angle. Bearings can be expressed as the direction angle. A bearing of S 10 degrees W, for example, would be expressed as a direction angle of N 80 degrees W.In this problem, the bearing is already given as S 10 degrees W. To convert it into a direction angle, we have to take its complement angle with respect to North. Therefore, 90°- 10° = 80°. Thus, the direction angle is N 80° W. Therefore, a bearing of S 10 degrees W would be written as a direction angle of N 80° W.
To know more about angle visit :
https://brainly.com/question/2005491
#SPJ11
Let R = {(x, y)|0 ≤ x ≤ 2,0 ≤ y ≤ 1}. Evaluate ∫∫ R x √1-y dA.
Answers
The value of the double integral ∫∫R x √(1-y) dA over the region R is 4.
To evaluate the double integral ∫∫R x √(1-y) dA, where R is the region defined as R = {(x, y) | 0 ≤ x ≤ 2, 0 ≤ y ≤ 1}, we need to integrate the given function over the region R.
We can rewrite the integral as follows:
∫∫R x √(1-y) dA = ∫₀¹ ∫₀² x √(1-y) dx dy
To evaluate this integral, we can perform the integration in two steps.
Step 1: Integrate with respect to x from 0 to 2 while treating y as a constant:
∫₀² x √(1-y) dx = [x²/2 √(1-y)]₀² = (2²/2 √(1-y)) - (0²/2 √(1-y)) = 2 √(1-y)
Step 2: Integrate the result from step 1 with respect to y from 0 to 1:
∫₀¹ 2 √(1-y) dy = 2 ∫₀¹ √(1-y) dy
To simplify this integral, we can use a trigonometric substitution. Let's substitute y = sin²θ, then dy = 2sinθcosθ dθ:
∫₀¹ 2 √(1-y) dy = 2 ∫₀¹ √(1-sin²θ) (2sinθcosθ) dθ
= 4 ∫₀¹ cosθ cosθ dθ
= 4 ∫₀¹ cos²θ dθ
Using the identity cos²θ = (1 + cos2θ)/2, we have:
4 ∫₀¹ cos²θ dθ = 4 ∫₀¹ (1 + cos2θ)/2 dθ
= 2 ∫₀¹ (1 + cos2θ) dθ
= 2 [θ + (sin2θ)/2]₀¹
= 2 (1 + (sin2 - sin0)/2)
= 2 (1 + (sin2 - 0)/2)
= 2 (1 + sin2)
Now, we need to substitute back y = sin²θ into our result:
2 (1 + sin2) = 2 (1 + sin²(π/2))
= 2 (1 + 1²)
= 2 (1 + 1)
= 4
Learn more about integral here:
https://brainly.com/question/18125359
#SPJ11
Problem 2. (1 point)
Consider the initial value problem
y" + 4y = 16t,
y(0) 9, y(0) 6.
a. Take the Laplace transform of both sides of the given differential equation to create the corresponding algebraic equation. Denote the Laplace transform of y(t) by Y(s). Do not move any terms from one side of the equation to the other (until you get to part (b) below).
b. Solve your equation for Y(s).
Y(s) = L {y(t)}
c. Take the inverse Laplace transform of both sides of the previous equation to solve for y(t).
y(t) =
Note: You can earn partial credit on this problem.
preview answers
Answers
Given Initial value problem:y" + 4y = 16ty(0) = 9, y'(0) = 6a) .
Take Laplace transform of both sides of the differential equation using L{y(t)} = Y(s)
Laplace transform of y” and y is as follows:
L(y”) = s²Y(s) - sy(0) - y’(0) = s²Y(s) - 9s - 6
Summary: To summarize, Laplace Transform and inverse Laplace Transform has been used to solve the given Initial value problem.
Learn more about Laplace transform click here:
https://brainly.com/question/29583725
#SPJ11
An aircraft company has their flight data as shown in the table below, where a forward flight from A to B will take 4 miles and a return B to A will take 3 miles.
A B C D
A 4 3 1
B 3 3
C 3 3 3
D 2 5 2
11. With the above information provided, draw a graph for the data provided. Indicate the weights on them. [5mark].
12. Produce the adjacency matrix for your graph drawn [5marks].
13. Find the shortest path in your graph and show the vertices and edges [5marks].
Answers
The graph represents the flight data of an aircraft company, where vertices represent locations (A, B, C, D) and edges represent flights between the locations. The numbers next to the edges represent the distances or weights of the flights. The graph visually represents the connections and distances between the locations.
11. Graph representation with weights:
```
(4) A ---- B (3)
| \ | / |
(1) \ (3)/ | (5)
| (3) (2)
C ---- D
```
In the graph above, each vertex represents a location (A, B, C, D), and the edges represent the flights between the locations. The numbers next to the edges represent the distances (weights) of the flights.
12. Adjacency matrix:
```
A B C D
A 0 4 3 1
B 3 0 3 0
C 0 3 0 3
D 2 5 2 0
```
The adjacency matrix is a square matrix where the rows and columns correspond to the vertices of the graph. Each entry in the matrix represents the weight or distance between the corresponding vertices. In this case, the values in the matrix indicate the distances between the locations.
13. Shortest path:
To find the shortest path in the graph, we can use algorithms such as Dijkstra's algorithm or the Floyd-Warshall algorithm. Without specifying the start and end vertices or the specific criteria for determining the shortest path (e.g., minimum distance or minimum number of edges), it is not possible to provide the vertices and edges of the shortest path.
Learn more about matrix : brainly.com/question/28180105
#SPJ11
A coin is thrown until a head occurs and the number X of tosses recorded. After Iepeating the experiment 256 times, we obtained the following results: 1 2 3 4 5 6 7 8 1136 60 34 12 9 1 3 1 Test the hypothesis, at the 0.05 level of significance, that the observed distribution of X may be fitted by the geometric distribution g(x: 1/2), x= 1, 2, 3,....
Answers
There is insufficient evidence to conclude that the observed distribution of X is not fitted by the geometric distribution.
How to explain the informationThe chi-square test statistic is calculated as follows:
χ² = Σ(O - E)² / E
The chi-square test statistic is calculated as follows:
χ² = (136 - 128)² / 128 + (60 - 64)² / 64 + (34 - 32)² / 32 + (12 - 16)² / 16 + (9 - 8)² / 8 + (1 - 4)² / 4 + (3 - 2)² / 2 + (1 - 1)² / 1
= 3.125
The p-value for the chi-square test statistic is calculated as follows:
p-value = 1 - p(χ² ≥ 3.125)
The degrees of freedom in this case is 7 (8 - 1). The p-value for 7 degrees of freedom and a chi-square statistic of 3.125 is 0.87.
Since the p-value (0.87) is greater than the level of significance (0.05), we fail to reject the null hypothesis. Therefore, there is insufficient evidence to conclude that the observed distribution of X is not fitted by the geometric distribution
Learn more about statistic on
https://brainly.com/question/15525560
#SPJ4
Evaluate S (y + x - 4ix)dz where c is represented by: C1: The straight line from Z = 0 to Z = 1 + i Cz: Along the imiginary axis from Z = 0 to Z = i. -
Answers
The value of the given line integral over the paths C1 and Cz is 4 - 2i, respectively.
The given integral is as follows;
S (y + x - 4ix)dz
We need to evaluate the given integral over two contours C1 and Cz.
As per the given information, we need to find the line integrals over the straight line from Z = 0 to Z = 1 + i and the imaginary axis from Z = 0 to Z = i.
Thus, let's evaluate the integral over each of these paths separately.
Integral over C1:
Parametric equations of the line joining the points Z = 0 and Z = 1 + i are as follows;
Z = 0 + t(1+i)
= t + it, 0≤t≤1
Thus, the given integral over the path C1 becomes;
∫c1(y + x - 4ix)dz=∫0¹+¹i(y + x - 4ix)(1+i)dt
= ∫0¹+¹i[(t-t)-(4i.t).(1+i)](1+i)dt
= ∫0¹+¹i[-4it-4i².t](1+i)dt
= ∫0¹+¹i[4t + 4t]dt
= 8∫0¹t dt
= 8[1/2t²]0¹= 4
Integral over Cz: Parametric equation of the path Cz is as follows; Z = ti, 0≤t≤1
Thus, the given integral over the path Cz becomes;
∫Cz(y + x - 4ix)dz
=∫0¹(y + x - 4ix).i dt
= ∫0¹[(0+t-4it).i]dt
= ∫0¹-4t dt
= [-2t²]0¹
= -2
Know more about the line integral
https://brainly.com/question/28381095
#SPJ11
Suppose you deposit $1000 at 5% interest compounded continously. Find the average value of your account during the first 4 years.
Answers
If you deposit $1000 at a continuous compounding interest rate of 5%, the average value of your account during the first 4 years can be calculated using the formula for continuous compounding.
Continuous compounding is calculated using the formula [tex]A = P * e^{rt}[/tex], where A is the final amount, P is the principal amount (initial deposit), e is the mathematical constant approximately equal to 2.71828, r is the interest rate, and t is the time period. In this case, P = $1000, r = 5% = 0.05, and t = 4 years.
Substituting these values into the formula, we have [tex]A = 1000 * e^{0.05 * 4}[/tex]. Evaluating the exponent, we get [tex]A = 1000 * e^{0.2}[/tex]. Using a calculator or approximation, [tex]e^{0.2}[/tex] is approximately 1.22140. Therefore, A ≈ 1000 * 1.22140 ≈ $1221.40.
To calculate the average value, we divide the final amount by the time period. So, the average value of the account during the first 4 years is $1221.40 / 4 ≈ $305.35. Hence, the average value of your account during the first 4 years would be approximately $305.35.
To learn more about continuous compounding visit:
brainly.com/question/31444739
#SPJ11